The GSoC coding period has ended last Monday. In this blog post, I will summarize what I have done during the summer, to give a general idea of what you can expect from a future version of Nepomuk, if my work is accepted by the Nepomuk maintainers.
The source code of the first two projects is available in the steckdenis-gsoc2013 branches of the nepomuk-core and nepomuk-widgets Git repositories. The browser plugin can be found in the scratch/dsteckelmacher/nepomukintegration.git scratch repository.
The Nepomuk Query Parser
The first part of my GSoC project was to implement a new user query parser for Nepomuk. This parser is responsible for translating queries entered by the user into a formal representation suitable for querying the Nepomuk database.
Project Goals
The current version of the parser (that is used for years now) is based on regular expressions. It recognizes a language close to what you can use on Google ("foo -bar title:something"). At the beginning of the project, Vishesh Handa explained me that this parser has limitations (it is not able to parse file sizes, and its parsing of date-time is a bit special, the parser tries many formats in an arbitrary and locale-independent order), and that its syntax is not very user-friendly. We agreed on implementing a parser that has a syntax more close to natural language, a syntax simple to understand and that doesn't require the user to read a big book before being able to perform queries.
The "new" query parser, as I name it, is based on pattern-matching. My first idea was to implement a real parser using state-of-the-art parsing techniques like Abstract Syntax Trees and a formal grammar, but these kinds of languages are not very user-friendly and are more suitable for programming languages, or anything that must have a precise sense of correctness and a defined meaning. The new parser aims for being user-friendly and accepting anything the user can enter, without the possibility of a parse error.
Recognizing Human Writing
During the spring, I developed a human date-time parser, that is to say a parser for date-times expressed like "first week of last month". Parsing such strings can nearly be considered as artificial intelligence, a field that greatly interests me. The way a human understands what is said or written always bothered me.
The literature regarding this subject is very rich, and complex algorithms can be used. More simple ones are possible when less precision is needed, and parsing search queries doesn't need a huge amount of precision. This allowed me to simply consider that as humans learn a language by memorizing the signification of words, the structure of sentences, and how patterns map to a signification ("X's Y" = "the Y of X" = Y.owner: X, X.has: Y), a computer could do the same.
I therefore implemented the date-time parser as a pattern-matcher. The parser considers the full string, and tries to find information in it. When words are matched against patterns, they are removed from the string. This way, the string contains less and less information, and the parsing stops when everything is removed. For instance, "first Monday of last month" contains two pieces of information : we talk about the first Monday of something, and this something likely is last month. The parser simply ignores everything it doesn't understand. A human confronted to a language he or she doesn't completely understand also works this way : a complete sentence is understood as "Warning, ... due to works ... metro stopped ... we apologize ...".
Matching patterns
As the date-time parser worked fairly well, I used the same algorithm for the Nepomuk query parser. The user query is split by words (if the user's locale doesn't separate words, the query is split by characters), that are used to build Nepomuk terms. At this step, the query looks for documents containing everything you typed. The query is already valid.
Next, the parser tries to recognize patterns, that are fully translatable (the order of the words can be rearranged, synonyms are handled, and multiple patterns can be associated with the same meaning). When a pattern is recognized, placeholders are used and the pattern is replaced by its parsed meaning. For instance, "tagged as X" is recognized in "Nepomuk, tagged as Important", and is replaced by a property comparison.
Because matched patterns are replaced with their parsed value (and not discarded as in the date-time parser), patterns can be nested. For instance, "size > 2M" contains three patterns: "2M" that is replaced by "filesize=2000000", "> comparison" that is replaced by "filesize>=2000000", and finally "size comparison" that is replaced by "nfo:fileSize >= 2000000". This also works for nested queries. A pattern like "related to %% ," matches "related to" followed by any number of terms, then either the end of the string or a comma. The terms matched by %% are all fed to the C++ rule implementing the pattern, that can concatenate them in a AND and use them as a simple value for a relatedTo comparison.
When every possible pattern has been tried, the input is considered to be parsed and is returned to the caller. The parser did its job.
What is a bit special with this parser is that matching patterns looks like matching regular expressions. Sure, patterns are more specific than regular expressions (and to be complete, regular expressions can be used in patterns, so that the translators do not need to explicitly write the dozens of forms a word can take in some languages), but it's the same spirit. This parser, even though not based on regular expressions anymore, and more robust, is not following a precisely defined syntax. It's up to the translators to write rules (the syntax is very simple), and each language can have its own "syntax". I find that way more user-friendly than a syntax fixed in stone.
The Query Builder Widget
The second part of the project was to implement a query builder widget. This widget is responsible for helping the user to enter queries. The first help is syntax-highlighting: the widget highlights what is recognized by the parser, so that the user can discover that things like "modified last week" (yes, I ported the human date-time parser to the new infrastructure) is understood by the parser and can be used when needed. The second help is auto-completion: the widget shows what patterns correspond to what has been written. For instance, entering "tagged" yields "tagged as
There is no complex (or boring, depending on your point of view) algorithm to explain in this part. The code is simple, and what took time was to design a user-friendly widget that is actually useful without getting in the way of the user. A picture is worth a thousand words:
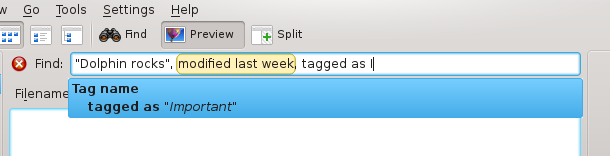
And in French:

A Firefox and Konqueror Plugin Indexing User Emails
At the middle of August, most of the first two parts of my GSoC project were nearly completed. The rest of the coding period was dedicated to bug fixes (there were many small and difficult-to-fix bugs that only happened on select queries). I also added unit tests for the parser, and I submitted a patch to Dolphin to use the query builder widget in it (see the screen-shot above).
The problem is that it is impossible to write unit tests during a full month, especially when the project tested was developed during two months. I therefore decided to find something I could do and that would benefit to Nepomuk.
I stared with the observation that many users, even my Computer Science class mates, use webmails. Nearly nobody use desktop mail clients anymore, and it is a shame given how useful they are. Moreover, people that use mail clients, even on Linux, don't all use KMail (there are GNOME users or KDE users that are used to Mutt or Thunderbird, or that simply don't want to use KMail). This observation made me think that only a small portion of the KDE users have their mails indexed in Nepomuk (by Akonadi), and therefore that email-related queries enabled by the new query parser are of no use to the others.
The goal of my project was to seamlessly allow these users to enjoy the features of Nepomuk. I did not want to oblige them to enter personal identification data (like POP/IMAP account names, servers and passwords) every time they open their KDE session or at the installation of their Linux distribution. Everything had to be completely transparent, without the need of any password.
The only solution I have found is to develop a browser plugin that monitors the activity of the user and recognizes when he or she is visiting a webmail. When it is the case, a webmail-dependent Javascript snippet is run to extract the mails displayed on the page. Currently supported webmails are Yahoo! Mail (in French), Roundcube and Outlook. GMail can also be parsed but its insane use of AJAX and asynchronous queries make it difficult to detect when the page has changed, and when the parser must be re-run on it.
A nice side-effect of this project is that Nepomuk is now able to index e-mails handled by Thunderbird or any other mail client, because I implemented a MIME/mbox file indexer.
More information about this project, that is still in an experimental state, can be found in this blog post.
Future Work
I now have a KDE Developer account, and I want to use it to improve KDE. My studies require a fair amount of work, but I will try to work on two projects that interest me:
- As suggested by Vishesh Handa, Nepomuk needs a good MS Office file indexer (able to parse the old binary formats still widely used). I have seen in the Calligra source code that a library able to parse these files is available, and I will try to use it (at least to extract the plain text content of the files).
- The pattern matcher I use in the query parser could be useful to other projects. I will see if it is possible to split it out of Nepomuk (or to develop a standalone version) and to make it available as a shared library, that could be used by other applications. The date-time and miscellaneous parsing passes (like the recognition of numbers and file sizes) will be available in this library, as they can be useful. I hope that people will be able to develop interesting applications with this parser.
So, stay tuned, and you can monitor my blog for activity on other projects (Planet KDE only shows blog posts related to KDE).