Finishing Touches and GMail
It has been a long time since my last blog post, but that doesn't mean nothing new has happened. In addition to fine-tuning the new Nepomuk Query Parser, I also try to write a Konqueror plugin that detects emails on common webmails and that index them in Nepomuk.
Fine-Tuning of the Query Parser
At the beginning of August, the query parser was already in quite a good shape. It was able to parse many queries in English, and I translated it into French the check that everything goes well. The first thing I discovered is that even if the translation operation was easy, it could be even better.
The problem was that the pattern matcher syntax was not adapted to languages with rich "declination". In English, adjectives are always spelled the same, independently of the words around them. In French, adjectives can have four forms, as they have a genre (English people always find funny that "A car is a lady in French"), and a number (the singular form is different from the plural one).
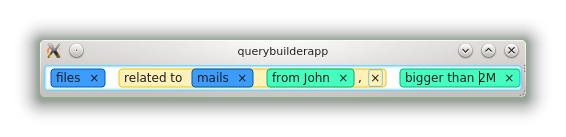
An example shows the problem better: consider the "modified|changed at %1" pattern, that matches "modified at 3.20pm" for instance. In English, two different adjectives are given, and the pattern works well for "files modified at ..." and "file modified at ...". In French, the pattern needs to accommodate the four forms that each adjective can take. It becomes "modifié|modifiée|modifiés|modifiées|changé|changée|changés|changées à %1". It's quite long, isn't it ?
The first step towards a solution is to allow regular expressions in patterns. The pattern in French now becomes "modifiée?s?|changée?s? à %1", its length is again under control. Regular expressions is the best I can give to translators, even if I think that many languages are still too complex to have each word expressed using a single expression. That is not a problem as it is still possible to use several expressions in a single pattern, so at worst the translators just need to write the 60 forms of their words, separated by pipes.

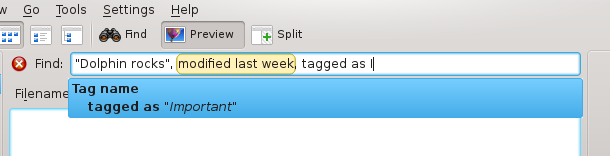
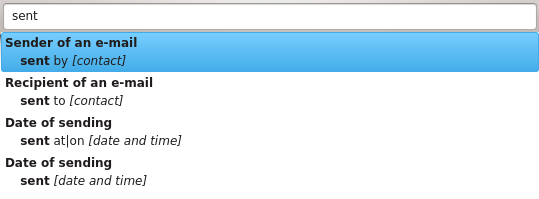
The problem of this solution is that the pattern is shown to the user, as you can see on the above image. Patterns that don't use regular expressions are nice to display (they are words separated by pipes), but regular expressions are way more difficult to understand. Now that patterns are shorter but not user-friendly anymore, I needed to find a way not to have them displayed.
This is done in two steps. The first one is that the user input is displayed when possible. If the user has typed "Modified at", the auto-completion box will show "Modified at", not "modified|created at|on". This already simplifies the auto-completion box, and has the nice property of respecting the case and the exact spelling the user used.
The second step is to display only one possible literal per term after the user query. If the pattern is "not touched|modified|changed since|after %1" and the user entered "not modified", the completion proposal will be "not modified since [something]". Translators can now hide the regular expressions: they just have to start their list of regular expressions with a simple nice word, that serves as a "title": "modifiée?s?|changée?s? à %1" becomes "modifié|modifiée?s?|changée?s? à %1", and the auto-completion popup will only display "modifié", never the following regular expressions.
Extracting Information from Web Pages using Javascript
By "parsing", I mean "recognizing the content of specific elements of a page". At the beginning of the month, I started to experiment with extracting emails from webmails and indexing them in Nepomuk. The first extractor I made is the one for Yahoo! Mail Neo (the French version). This extractor works very well.
After that, I wanted to quickly implement a parser for GMail and Outlook, two of the most used webmails. I started with GMail, and discovered that the current infrastructure did not allow to parse it. The problem is that this webmail is very complex. For instance, an email can be displayed on its own page (new messages from unknown contacts) or in a discussion (when you reply to someone). The discussion is especially difficult to parse as information about the emails is scattered on the whole page: the content of the messages is in the discussion itself, but the meta-data (date, sender, title) is contained in elements very far from the messages in the DOM tree.
I therefore decided to replace my own JSON-based syntax with full-fledged Javascript. QtScript made that very easy, and in one day, I had the Yahoo! Mail parser rewritten in Javascript:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | ({
urls: ["*.mail.yahoo.com/neo/*"],
emails: function(document) {
var content_nodes = document.findAll("div.message.content");
var mails = new Array();
var field = function(parent, name, attribute) {
var nodes = parent.findAll("div.info.expanded ul[aria-labelledby=\"hdr-" + name + "\"] a");
if (attribute == "") {
return contentOf(nodes);
} else {
return attributeOf(nodes, attribute);
}
}
for (var i=0; i<content_nodes.length; ++i) {
var content_node = content_nodes[i];
var date = content_node.findFirst("div.info div.date");
var title = content_node.findFirst("div.info h3 span.txt");
var content = content_node.findFirst("div.msg-body");
if (date == null || title == null || content == null) {
continue;
}
mails[i] = {
title: title.content(),
content: content.content(),
date: stringToDate(date.content(), "ddd, d MMM. yyyy à h:mm", "fr"),
from_name: field(content_node, "from", ""),
from_addr: field(content_node, "from", "title"),
to_name: field(content_node, "to", ""),
to_addr: field(content_node, "to", "title"),
cc_name: field(content_node, "cc", ""),
cc_addr: field(content_node, "cc", "title")
}
}
return mails;
}
})
|
The JS rules can use everything exposed by QtScript (I think that it is standard core EcmaScript), plus some helper functions implemented in C++. The DOM Elements are represented by JSElement objects (each JSElement being either a JSElementKHTML or a JSElementWebkit), and they have a small set of methods:
tagName()that returns the tag name of the elementcontent()that returns the text content of the elementattribute(name)to get the value of an attributefindAll(selector)that returns the list of all child elements matching a CSS rulefindFirst(selector)that returns the first element returned byfindAll, ornullif the list of matched elements is empty
contentOf takes a list of elements and returns a list containing their content, and attributeOf does the same for an attribute. Finally, stringToDate(string, format, lang) converts a string to a date using a specified locale. Internally, QLocale::toDateTime is used.
Detecting Changes in the DOM Tree of a Document
After having implemented rules written in Javascript, I decided to try again to parse GMail. Its rule is a bit more complex than the one of Yahoo, but is was possible to implement.
The problem is that when I tried to test my rule, nothing happened. Why ? Because the Konqueror plugin needs to detect when the DOM tree of a page changes. This notification triggers a re-parse of the page, and the parsing rules can detect potential new emails. In Yahoo! Mail, the DOM changes are correctly detected: they are preceded by a network request that can be detected by using the KParts::ReadOnlyPart::started(KJob *) signal. GMail does not trigger this signal, though. By sniffing my network, I discovered that GMail also performs network queries just before updating its DOM tree, but these queries are not detected. I don't know why and I have asked on the kde-devel mailing-list. If you have a solution for reliably detecting DOM tree changes, you will have my eternal gratitude.
I will try to solve this "GMail problem" in the coming days. After that, I will implement rules for Outlook and Roundcube. This will allow me to check that the current Javascript-based infrastructure is right, and that I can proceed to the development of a Firefox plugin. If you have ideas regarding the Nepomuk Query Parser or find bugs in it, don't hesitate to tell me as I very muck like to work on it, and I want to make it the best possible.