The coding period of this year's Google Summer of Code starts this Monday, and I have just finished my exams. It is a good time to start working on my project, a Nepomuk query parser.
When I learned that I was accepted as a GSoC student, I began defining a grammar that will be used to parse Nepomuk search queries. I sent several mails to the nepomuk mailing list, and received very good feedback.
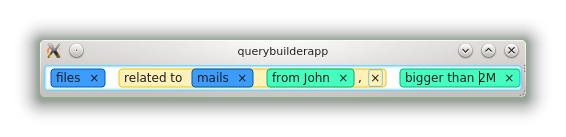
My first mail described a very formal grammar, very much like the one used by the current parser, that uses a key:value syntax (for instance, reservation house hasTag:holidays). The first comments said that this was not user-friendly enough, and pointed me to alternative syntaxes. In fact, I had only a small idea of what would be user-friendly, so these examples greatly helped me.
I then proposed a small modification of my syntax. The first version was purely key:value based, and relied heavily on special characters, parenthesis, colons, operators, etc. The second version made most of these special characters optional, and allowed keys to span multiples words. sent_by:Me could then be replaced by sent by Me, a far more user-friendly syntax.
Simplifying the Parser
The problem with my second syntax is that it is fairly complex. It is a full formal grammar, with nested queries, and even with that the parser is unable to parse something that is not a sequence of key with spaces value statements. In English, nearly everything can be expressed with these kinds of sequences, but other languages in the world need to split the key around the value (if they have detached postfixes for instance), and even "sent last week to Jimmy" cannot be parsed, even if it is a simple rewording of "sent to Jimmy, sent last week".
After having discussed a bit with Vishesh Handa, my mentor, I began thinking about how a parser could handle these kinds of weird queries. Vishesh also told me that I do not need to keep the new syntax compatible with the old one, so I can simplify my reflection.
Before being accepted as a GSoC student, I developed a small library that parses human-entered date-times. "first Monday of next month" will be parsed to the date of the first Monday of next month. This "parser" is not really one following the strict definition of the term. The date-time is not parsed from left to right (from start to finish), but information is cherry-picked. Rules say for instance that "first X", where X is a day, sets the day of the current period to 0. "next X" is also a rules, and here is responsible for incrementing the month number.
This approach is not very formal, but allows rules to be written independently of the parser. The parser ceases to be a parser and becomes a scripting environment. In fact, the human date-time parser used per-locale XML files and relied on KDE's KCalendarSystem class.
For the Nepomuk query parser, I plan to use an approach like this, but a bit enhanced. The idea of rules is kept, but rules become more powerful and less painful to translate.
Architecture of the Parser
I will explain the general architecture of the parser using an example query made of words, English-specific constructs and key/value pairs:
| e-mails sent by Jimmy, containing "hot dogs", and received before June 13
|
Don't be afraid of this query, the plain list of keywords is also recognized by the parser.
The first step is the splitting of the query into words. The split is operated at every character for which QChar::isSpace returns true. Normally, this covers every spacing character for every language handled by the Unicode character set.
When the words are split, the parser uses them to build a list of Nepomuk2::Query::LiteralTerms. This list can be used to search for documents by keywords. The next passes are only here in order to improve the search results, and also to change the simple literal values into something more precise, that can be used for auto-completion when needed.
| (e-mails) (sent) (by) (Jimmy) (,) (containing) (hot dogs) (and) (received) (before) (June) (13)
|
The first pass transforms string constants into constants of a more suitable type. For instance, "13" is converted to 13 (the integer), "3.14" becomes a double, "2MB" becomes 2.000.000, and finally "2MiB" is converted to 2.097.152.
| (e-mails) (sent) (by) (Jimmy) (,) (containing) (hot dogs) (and) (received) (before) (June) (int:13)
|
Another pass that I have already implemented is what I call type hints. If you have a generic search interface (like KRunner or the equivalent in Plasma Active), the queries entered in them can concern any data indexed on the computer, like files, e-mails, photos, etc. Even if we only think about Dolphin, Nepomuk knows that a file is not only a file, but a document, a picture, a movie, etc. This second pass recognizes type hints in the query and transforms them into filters on the document type.
| (ResourceType=nmo:Email) (sent) (by) (Jimmy) (,) (containing) (hot dogs) (and) (received) (before) (June) (int:13)
|
The third pass already implemented matches "sent by X" and "from X" and adds a filter on the sender of an e-mail
| (ResourceType=nmo:Email) (nmo:messageFrom=Jimmy) (,) (containing) (hot dogs) (and) (received) (before) (June) (int:13)
|
Currently, my small experiment does not get the list of known contacts from Nepomuk, but instead tries to directly compare the nmo:messageFrom property with a string. I is not correct and will not work, but I first wanted to have a working parser before being able to generate real queries.
The next passes are not already implemented but will be in the coming days or weeks. One of them could match "containing X" and change the query like this (bif:contains is what the current parser seems to use to match documents containing something, but there may be a better way of doing this):
| (ResourceType=nmo:Email) (nmo:messageFrom=Jimmy) (,) (bif:contains="hot dogs") (and) (received) (before) (June) (int:13)
|
The next one matches a day of a month. In English, the month name comes before the day number, but other languages do things differently. This kind of pattern matching can be done using a small pattern language developed for the parser. Each word in the pattern is either an immediate value (it matches a literal value having exactly this value) or a constraint on the term to be matched. For instance, June <integer0> matches "June 13". The 0 after integer allows the translators to move placeholders around in the pattern, everything will be kept ordered on the C++ side.
So, a day-of-month rule could be <string0> <integer1> in English. The C++ handler for this pattern will first check that string0 is a month name and integer1 is comprised between 1 and 31. Then, the according filter can be output. This rule can be translated in French to <integer1> <string0> as month names and day numbers are inverted in French (we say "13 Juin"). In fact, even in English the phrase can be "13th of June". No problem, the parser accepts multiple patterns for a rule:
| d->runPass(d->pass_dayofmonth, i18nc(
"Day number of a month",
"<string0> <integer1>|<integer1> (?:th|rd|nd) of <string0>|<integer1> <string0>"
), 2); // 2 = there are two arguments in the pattern
|
Translators are free to add as many rules as they want. Notice that regular expressions will be allowed (currently, they are not yet implemented). Another modification to the current parser that has to be done is to split "3rd" into "3" and "rd". This could also be used to split "3GB" into "3" and "GB", thus simplifying the handling of file sizes.
With that said, the query is now:
| (ResourceType=nmo:Email) (nmo:messageFrom=Jimmy) (,) (bif:contains="hot dogs") (and) (received) (before) (date:2013-06-13)
|
The last thing that would be nice to have parsed is the "received before" thing. Here, the parser needs to parse "before " to produce a new date, but with a hint that the comparison to be done with this date is not the equality, but an ordered relation. Then, the parser has to match "received " and do the actual comparison:
| (ResourceType=nmo:Email) (nmo:messageFrom=Jimmy) (,) (bif:contains="hot dogs") (and) (nmo:receivedDate<=2013-06-13)
|
Now, there is nothing more to do. The parser stops trying rules (it does so in a loop, like optimization passes of a compiler, each rule being able to possibly alter the query and to expose further refinements), and proceeds to the final step: literal values smaller than a minimum size are removed. This removes the comma and the and. We get the final query:
| (ResourceType=nmo:Email) AND (nmo:messageFrom=contact:Jimmy) AND (bif:contains=string:"hot dogs") AND (nmo:receivedDate<=date:2013-06-13)
|
If there was a literal value bigger than the threshold and not matched to anything, it would have been matched against its default property. If the literal value is a string, its default property is bif:contains. For a date, it is a set of properties like the date of creation/receiving, modification, etc.
Current state and future plans
Currently, the parser is completely experimental and cannot be used to do anything even remotely useful. I blog about it in order to have comments about the current implementation direction, and to present how I see the parser. I like to communicate regularly on my blog, my average for my GSoC two years ago was one blog post per day or two. Feel free to comment and to find examples of difficult to parse queries, I will try to organize and architecture the parser in order to have it able to parse your query (if it is user-friendly enough).
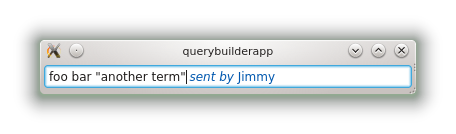
Another point is that my GSoC project is also about implementing an auto-completed input field. I currently have thought of two strategies that can be used to present auto-completion propositions to the user:
- Patterns are matched from left to right. If the start of a pattern matches (say, more than 50%, or anything containing an immediate value like a keyword), the end of the pattern can be presented to the user. For instance, if I enter "sent by", the parser knows that the last part of the pattern is a contact, and the auto-complete box can show the list of my contacts.
- Terms are typed. When the user edits the query, his or her cursor is not at the end of the input field, and the parser must be more careful (the user may be breaking already-parsed statements or inserting things between them). The already-parsed terms can be used to know what the user is editing. If the user places its cursor on something that was found to be a date-time, a calendar can be shown.
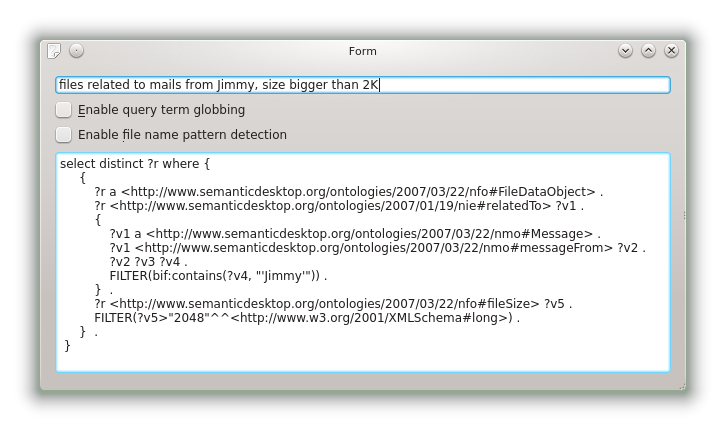
The current implementation is able to parse things like "mails sent by Jimmy", and gives the following result:
| <?xml version="1.0"?>
<type uri="http://www.semanticdesktop.org/ontologies/2007/03/22/nmo#Email"/>
<?xml version="1.0"?>
<comparison property="http://www.semanticdesktop.org/ontologies/2007/03/22/nmo#messageFrom" comparator="=" inverted="false">
<literal datatype="http://www.w3.org/2001/XMLSchema#string">Jimmy</literal>
</comparison>
|
I will post more details in the coming days, as I advance in the parser and solve different problems.