Translations and Better Auto-Completion
This blog post presents several small steps that made the new Nepomuk query parser closer to be useful for every user. The most important one is that its localization features work, the other is that the auto-completion now is more clean and elegant.
Before speaking of new features, a good news: my work now lives in the official Nepomuk repositories! I got a KDE Developer Account, and you can find everything in the steckdenis-gsoc2013 branches of nepomuk-core and nepomuk-widgets.
The Query Parser in French
Even if I don't live in France (I live in Brussels, Belgium), my native language is French. In fact, Belgium is a country where half the population speaks Dutch and the other half French. There is also a group of people speaking German. In Brussels, the capital, about 80% of the people speak French.
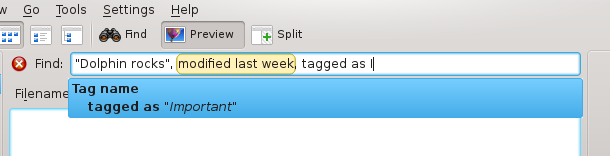
That's for the geolinguistics. What interests most readers is that I translated my Nepomuk query parser in French. This was quite easy: every translatable string is wrapped into a i18nc() call, and adding a small Messages.sh file in the Git repository enabled me to extract these messages using a script of the KDE Localization project. The translations were extracted into a .pot file, that I just had to edit using Lokalize. When every string was translated, I saved the file and installed it on the right place on my system.
The result is shown in the following screenshot, that will surely look familiar to French-speaking people:

The .pot are not in the Git repository because it does not belong there. When my work will be merged into the master branch of nepomuk-core, scripty (the script that updates translations on the KDE Git and SVN repositories) will extract the translatable strings and will put them on the SVN repository used by the KDE translators. Each language will then have its own translation of the parser.
Simplifying the Auto-Completion Box
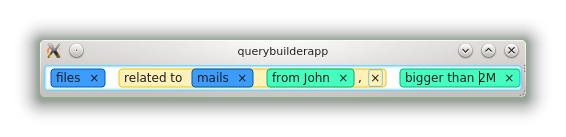
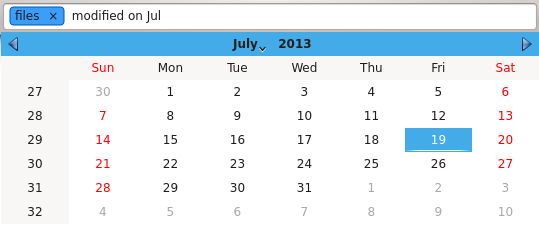
The auto-completion box as shown in this blog post was made of pages. The first one displayed patterns (what the user can enter and its meaning), the second one was used for strings (tag names or contacts), and the third one was a QCalendarWidget, that allowed the user to select a day.
Even if this worked, there were several problems in this approach. The first one is that the code was not very nice, there was duplication between the pages. Another problem was that the QCalendarWidget may not be compatible with other calendar systems. Finally, as you can see at the beginning of the blog post, the widget was not very nice. Sure, the page displaying patterns had charm, but the list of strings looked too simple.
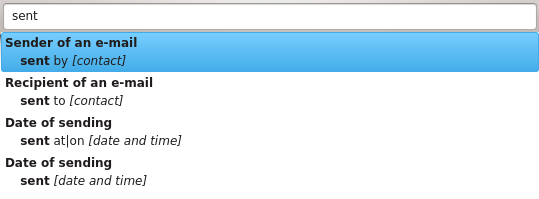
Another problem, that cannot be shown using screenshots, is that getting a list of strings is very difficult. As this list of strings replaces the list of patterns, there must be only one pattern in the list. This means that you won't get the list of your tags if your query is even slightly ambiguous, and it is easy to be ambiguous. For instance, "sent to" shows three patterns: "sent to [contact]", "to [contact]" (ignoring the "sent") and "sent [date-time]", as the pattern matched does not know that "to" will never be a valid date-time. In this case, even if you know what you want, the query builder with not show you anything.
The solution I adopted is to get rid of the pages. Now, the completion box only shows patterns (this was the nicest page). When values can be auto-completed, they are so directly in the pattern list. For instance, if you type "sent to Nep", the auto-completion box will show "sent to 'Nepomuk Mailing List'" and "to 'Nepomuk Mailing List'". This way, the user gets value proposals even if its query is slightly ambiguous. And this is nicer than a big list of strings without any formatting:

This change also removed hundreds of source lines of code. I'm always happy to improve things while removing lines. The only "regression" is that the calendar widget is gone, and I still need to find a way to tell the user that he or she can enter human date-times ("if you want to open a calendar to find what is the first Monday of next month, just type 'first Monday of next month'").
When KRunner Works out of the Box
After having integrated the query builder widget into Dolphin, I wanted to see if there was something needed to parse Nepomuk queries in KRunner. Before cloning any git repository, I tested my distribution KRunner. As I install my development libnepomukcore system-wide (this allows me to check that everything is binary-compatible), entering a query in KRunner yielded:

What a nice surprise! Nothing to do, KRunner is able to use my new parser without any modification. I thought that working on an already well-known library is a very pleasant experience, because you don't improve one application, but every application that uses the library. Furthermore, the fact that KRunner did not crash means that my work is fully binary compatible with the old query parser (as I reused its .h header, I was quite confident in that).
Other bugs fixed
The other changes don't deserve a screenshot. For instance, I fixed how date-time intervals are parsed (there was a typo that made weeks one-day long, and another one that inverted December and September) and I improved how relative weeks are handled. For instance, "second week of next month" now works as expected. This fix also simplified the code.
The query builder widget was also slightly improved. Its sizing is now more consistent, and I removed the sizeHint() method (that I simply ignore now). All in all, the parser and the query builder now work way better. I also added Doxygen comments to CompletionProposal. I still have to do that for the query builder widget itself.
Some days ago, I wondered if implementing a Firefox extension that recognized e-mails and contacts in webmails was a good idea. I read documentation about that and it seems possible, users using webmails will be able to enjoy the Nepomuk features. Before doing that, I will first check that nobody has done something like that. The KDE QuickGit for instance lists interesting repositories, like nepomuk-web-extractor.
I also add that if you have queries that you think the parser should be able to parse, don't hesitate to tell me. There may be whole classes of queries that I haven't thought of.