As my query parser begins to be useful and to work well, I want to start working on the syntax-highlighted input field. As I do not want to multiply the experimental repositories (people need to find them, to build them, and when the work is upstreamed, I have to put a big notice saying that the repository is outdated), I plan to develop the input field in a separate branch of nepomuk-widgets.
The syntax-highlighted input field needs to use the query parser. If the query parser remains in a separate Github repository, I have to add it as an external dependency in nepomuk-widgets. Furthermore, I think for some days now that it would be interesting to see how the new parser integrates with Nepomuk as a whole.
Merging git subtrees
- My branch of
nepomuk-core:gsoc2013ofhttp://public.steckdenis.be/git/nepomuk-core/. It will move to the official Nepomuk Core repository once I get a KDE developer account and the Nepomuk maintainers allow me to push the branch.
I love history. I think that big squashed merges are difficult to get reviewed because reviewers need to read and understand thousands of lines of code at once. When the development history is kept, it can be viewed progressively. The only problem is that development is never a straight line going towards the finished product. There are experiments, sometimes something gets reverted or canceled, or things simply change.
In the case of my parser, the grammar of the pattern matcher has changed after 2 days of development, and the pattern matcher became a class on its own a bit later. There are also parsing passes that got removed or merged into other ones (hourminute, that was responsible of recognizing hours and minutes, is now merged into datevalues, that assigns values to hours, minutes, seconds, and also days, months, weeks, etc).
I decided to add my parser into the Nepomuk Core source-tree, with its full history. I found some interesting instructions on Stack Overflow, and everything worked perfectly. Now, my branch of the nepomuk-core repository contains a new directory: libnepomukcore/queryparser/. All my files are there and build perfectly. I also removed the old query parser (it was just one file).
The new query parser is source- and binary-compatible with the old one. In fact, its .h header is the same as the one of the old parser. I simply copied it, and changed some parts of the documentation (the syntax is not the same, limitations are lifted, and other limitations are temporarily added).
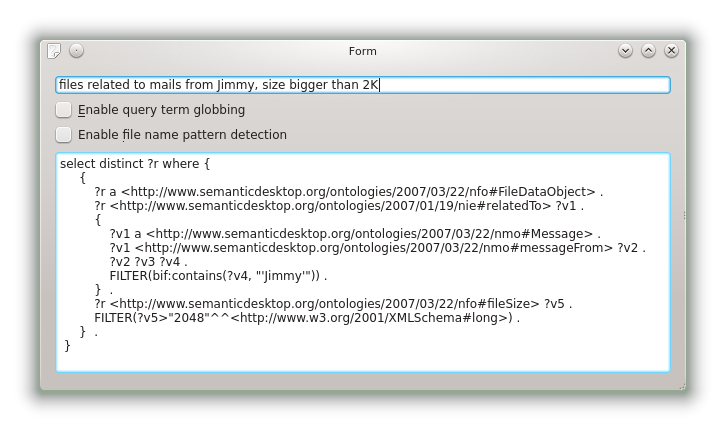
Building libnepomukcore was simple and there was no problem. I fixed two compiler warnings exposed by the use of GCC (I usually compile with Clang) and optimization flags that uncover reads of uninitialized variables. When everything was built, I was able to launch nepomukquerytester, a tool that allows me to enter queries and to get the resulting SPARQL query that will be sent to the storage backend:
Some days ago, Vishesh Handa developed a cool new utility called nepomuksearch. It is a command-line utility (with nice colors) that takes a query on its command line and outputs the corresponding documents. Without any modification, it was able to use my new parser to show my files. Keywords, properties, dates, everything work. I was able to list the files I modified yesterday simply by searching for "modified yesterday". Nice.
Now that the parser is merged into Nepomuk, I can build a libnepomukcore library that contains everything the syntax-highlighted input field needs.
Positional information
Another new feature of the past days is that the parser stores positional information into the terms it produces. A term is the data-structure used to represent a parsed query. There are literal terms (integers, strings, date-times), comparison terms, resource type terms ("mails" gives the hint that e-mails must be returned by the query), and logical terms (and, or, not), among others.
I have submitted a review request to the Nepomuk developer, asking them if I can add two fields to the base Term class. One of those fields is a position, the other is a length. They allow the parser to remember from which portion of the user query string it parsed terms.
Every term has positional information, not only literal ones. For instance, a comparison term covers the part of the user query that describes the comparison. For "mails sent by John", the comparison terms covers "sent by John", the resource type term is linked to "mails", and the literal term simply is "John".
With this tree of terms, each having positional information, it is possible to do a pretty neat syntax highlighting: use a different nice color for each term, and render literal terms in bold face. This way, the actual content (the literal terms) is clearly seen by the user, and he or she also sees if properties are correctly recognized. An example of highlighted query is "mails sent by John" (I used italics font instead of colors).
Syntax-highlighting is not the only way of representing this kind of information. For instance, Ivan Čukić proposed a very great user interface that you can see here. I really find it beautiful and congratulate Ivan for it! I will see how it could be implemented with my parser (that recognizes complex patterns, even mixed patterns where date-times are spread between property comparisons).
Timing
We are now at the end of the second week of the Google Summer of Code. My project is composed of two big parts:
- The query parser (in the sense of "something that takes a query string and produces a
Nepomuk2::Query::Queryobject") - A "query builder widget", a widget used by Dolphin when you click on "Search" and that allows the user to build queries without having to understand how the parser works. The query parser recognizes a language close to natural language, but this widget can also help the user by exposing auto-completion suggestions (tag names, contacts, file-names, date-time popups, etc), and decorating the input with some nice colors
The query parser is in good shape and is able to parse queries. When porting the unit tests from the old parser to the new one, I have found that some features still are lacking (like the recognition of file-name wild-cards), but it is already quite usable, and produces positional information.
The query builder widget will be very interesting to develop. The challenges will be graphical (the interface of Ivan is very nice but seems difficult to implement, and even more to implement right) and algorithmic, as the parser will need to be adapted (for instance, if a pattern like "sent by %1" only partially matches, it can be used to add a new auto-completion proposal).
I'm on holidays from July 3 to July 13, so there will be no new blog post during this period. Before that, I will try to advance as much as possible in the implementation of a nice query builder widget. I'm very excited, and nice-looking things always pleased me. After my holidays, I will have nearly two months and a half to finish the query builder widget, fix bugs, and integrate Nepomuk at interesting places (KRunner, Plasma Active, etc). I'm open to any suggestion.